One database for everything
Now integrating: archeology, archaeobotany, ichthyology, algology…

UniCatDB is a coherent yet flexible interdisciplinary storage solution for cataloging findings data of various research groups, focused mainly on green biology. Configurable by the researchers themselves, provides shared access enabling interoperability if desired, and is accessible by user-friendly interface on either desktop, laptop or tablet - both in the lab and on the go.
See how it works
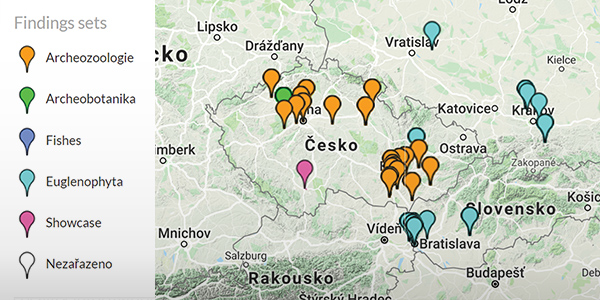
Data both in detail and in context
Integrating multiple data sources into a single catalog allows for getting a bigger picture. This will stand out especially when the data are visualized together on a map. Apart from simple display, the Map view of UniCatDB can also perform clustering which both simplifies overview over many records and provide basic frequency counts. However, none of these features prevent users studying individual records in full detail.
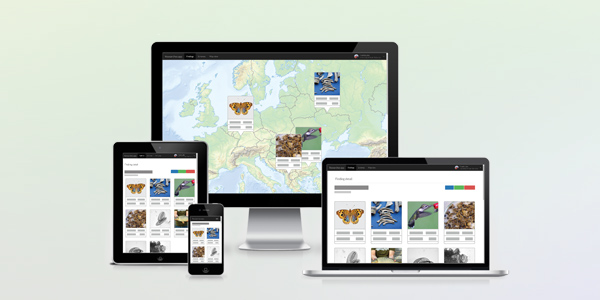
Database at your fingertips
Unifying diverse data sources under one user interface helps usability a lot – anyone who had to deal with inconsistent mess in spreadsheets would agree. UniCatDB has modern responsive web interface built according to contemporary standards which makes it usable on a wide range of devices including desktops, laptops, tablets and even smartphones. All you need to have is an internet connection and modern up-to-dated web browser.

Based on the cutting-edge technology and open standards for compatiblity
UniCatDB is implemented using the state-of-the-art technologies for forward compatibility. Application back-end is based on the .NET Core platform which enables deployment scenarios in Windows and Linux ecosystems, or in the cloud. Heavy work is done by the MongoDB, a No-SQL database, which provide flexible storage. Application front-end, built upon the React framework, provides a modern interface usable in various devices. UniCatDB is designed with extensibility in mind – an API is provided, which complies with the JSON API standard and OpenAPI Specification to allow interconnectivity with third-party systems.
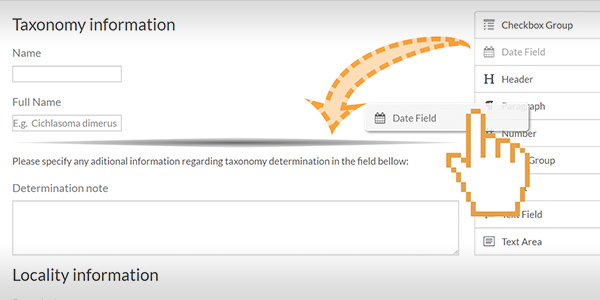
Flexibility for interdisciplinary usage made as easy as doing "drag-n-drop"
A database aggregating diverse data sources, needs flexible schema. Apart from a minimal common base, UniCatDB doesn’t impose any specific schema on the records it stores, allowing the data owners to define the schema they need. This rather technical process is greatly simplified by the user interface – building a schema is as easy as doing "drag-n-drop". This approach, however, is perfectly capable of producing complex schemas too, including advanced features such as grouping related data fields in several levels, setting validation rules, placing various additional information throughout the form to guide data acquisition staff, and many more.